Анализ данных эксперимента excel мнк. Метод наименьших квадратов в Excel. Регрессионный анализ. Включение надстройки «Поиск решения»
Одним из методов изучения стохастических связей между признаками является регрессионный анализ .
Регрессионный анализ представляет собой вывод уравнения регрессии, с помощью которого находится средняя величина случайной переменной (признака-результата), если величина другой (или других) переменных (признаков-факторов) известна. Он включает следующие этапы:
- выбор формы связи (вида аналитического уравнения регрессии);
- оценку параметров уравнения;
- оценку качества аналитического уравнения регрессии.
В случае линейной парной связи уравнение регрессии примет вид: y i =a+b·x i +u i . Параметры данного уравнения а и b оцениваются по данным статистического наблюдения x и y . Результатом такой оценки является уравнение: , где , - оценки параметров a и b , - значение результативного признака (переменной), полученное по уравнению регрессии (расчетное значение).
Наиболее часто для оценки параметров используют метод наименьших квадратов (МНК).
Метод наименьших квадратов дает наилучшие (состоятельные, эффективные и несмещенные) оценки параметров уравнения регрессии. Но только в том случае, если выполняются определенные предпосылки относительно случайного члена (u) и независимой переменной (x) (см. предпосылки МНК).
Задача оценивания параметров линейного парного уравнения методом наименьших квадратов
состоит в следующем: получить такие оценки параметров , , при которых сумма квадратов отклонений фактических значений результативного признака - y i от расчетных значений – минимальна.
Формально критерий МНК
можно записать так:  .
.
Классификация методов наименьших квадратов
- Метод наименьших квадратов.
- Метод максимального правдоподобия (для нормальной классической линейной модели регрессии постулируется нормальность регрессионных остатков).
- Обобщенный метод наименьших квадратов ОМНК применяется в случае автокорреляции ошибок и в случае гетероскедастичности.
- Метод взвешенных наименьших квадратов (частный случай ОМНК с гетероскедастичными остатками).
Проиллюстрируем суть классического метода наименьших квадратов графически
. Для этого построим точечный график по данным наблюдений (x i , y i , i=1;n) в прямоугольной системе координат (такой точечный график называют корреляционным полем). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов линия выбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.

Математическая запись данной задачи:  .
.
Значения y i и x i =1...n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров - , . Чтобы найти минимум функции 2-ух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е. 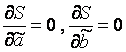 .
.
В результате получим систему из 2-ух нормальных линейных уравнений: 
Решая данную систему, найдем искомые оценки параметров:

Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм (возможно некоторое расхождение из-за округления расчетов).
Для расчета оценок параметров , можно построить таблицу 1.
Знак коэффициента регрессии b указывает направление связи (если b >0, связь прямая, если b <0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Формально значение параметра а – среднее значение y при х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра а не имеет смысла.
Оценка тесноты связи между признаками
осуществляется с помощью коэффициента линейной парной корреляции - r x,y .
Он может быть рассчитан по формуле:  . Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:
. Кроме того, коэффициент линейной парной корреляции может быть определен через коэффициент регрессии b:  .
.
Область допустимых значений линейного коэффициента парной корреляции от –1 до +1. Знак коэффициента корреляции указывает направление связи. Если r x, y >0, то связь прямая; если r x, y <0, то связь обратная.
Если данный коэффициент по модулю близок к единице, то связь между признаками может быть интерпретирована как довольно тесная линейная. Если его модуль равен единице ê r x , y ê =1, то связь между признаками функциональная линейная.
Если признаки х и y линейно независимы, то r x,y близок к 0.
Для расчета r x,y можно использовать также таблицу 1.
Для оценки качества полученного уравнения регрессии рассчитывают теоретический коэффициент детерминации – R 2 yx:
 ,
,
где d 2 – объясненная уравнением регрессии дисперсия y ;
e 2 - остаточная (необъясненная уравнением регрессии) дисперсия y ;
s 2 y - общая (полная) дисперсия y .
Коэффициент детерминации характеризует долю вариации (дисперсии) результативного признака y , объясняемую регрессией (а, следовательно, и фактором х), в общей вариации (дисперсии) y . Коэффициент детерминации R 2 yx принимает значения от 0 до 1. Соответственно величина 1-R 2 yx характеризует долю дисперсии y , вызванную влиянием прочих неучтенных в модели факторов и ошибками спецификации.
При парной линейной регрессии R 2 yx =r 2 yx .
Метод наименьших квадратов (МНК)
Система m линейных уравнений с n неизвестными имеет вид:
Возможны три случая: m В случае, если m>nи система является совместной, то матрица А имеет по крайней мере m - nлинейно зависимых строк. Здесь решение может быть получено отбором n любых линейно независимых уравнений (если они существуют)и применением формулы Х=А -1 ЧВ, то есть, сведением задачи к ранее решенной. При этом полученное решение всегда будет удовлетворять и остальным m - nуравнениям. Однако при применении компьютера удобнее использовать более общий подход - метод наименьших квадратов. Под алгебраическим методом наименьших квадратов понимается метод решения систем линейных уравнений путем минимизации евклидовой нормы Ax ? b? > inf . (1.2) Рассмотрим некоторый эксперимент, в ходе которого в моменты времени производится, например, измерение температуры Q(t). Пусть результаты измерений задаются массивом Допустим, что условия проведения эксперимента таковы, что измерения проводятся с заведомой погрешностью. В этих случаях закон изменения температуры Q(t) ищут с помощью некоторого полинома P(t) = + + + ... +, определяя неизвестные коэффициенты, ..., из тех соображений, чтобы величина E(, ...,), определяемая равенством гаусс алгебраический exel аппроксимация принимала минимальное значение. Поскольку минимизируется сумма квадратов, то этот метод называется аппроксимацией данных методом наименьших квадратов. Если заменить P(t) его выражением, то получим Поставим задачу определения массива так, чтобы величина была минимальна, т.е. определим массив методом наименьших квадратов. Для этого приравняем частные производные пок нулю: Если ввести m Ч n матрицу A = (), i = 1, 2..., m; j = 1, 2, ..., n, где I = 1, 2..., m; j = 1, 2, ..., n, то выписанное равенство примет вид Перепишем написанное равенство в терминах операций с матрицами. Имеем по определению умножения матрицы на столбец Для транспонированной матрицы аналогичное соотношение выглядит так Введем обозначение: i -ую компоненту вектора Ax будем обозначать В соответствии с выписанными матричными равенствами будем иметь В матричной форме это равенство перепишется в виде A T x=A T B (1.3) Здесь A - прямоугольная mЧ n матрица. Причем в задачах аппроксимации данных, как правило, m > n. Уравнение (1.3) называется нормальным уравнением. Можно было с самого начала, используя евклидову норму векторов, записать задачу в эквивалентной матричной форме: Наша цель минимизировать эту функцию по x. Для того чтобы в точке решения достигался минимум, первые производные по x в этой точке должны равняться нулю. Производные данной функции составляют 2A T B + 2A T Ax и поэтому решение должно удовлетворять системе линейных уравнений (A T A)x = (A T B). Эти уравнения называются нормальными уравнениями. Если A - mЧ n матрица, то A>A - n Ч n - матрица, т.е. матрица нормального уравнения всегда квадратная симметричная матрица. Более того, она обладает свойством положительной определенности в том смысле, что (A>Ax, x) = (Ax, Ax) ? 0. Замечание. Иногда решение уравнения вида (1.3) называют решением систе- мы Ax = В, где A прямоугольная m Ч n (m > n) матрица методом наименьших квадратов. Задачу наименьших квадратов можно графически интерпретировать как минимизацию вертикальных расстояний от точек данных до модельной кривой (см. рис.1.1). Эта идея основана на предположении, что все ошибки в аппроксимации соответствуют ошибкам в наблюдениях. Если имеются также ошибки в независимых переменных, то может оказаться более уместным минимизировать евклидово расстояние от данных до модели. Приведенный ниже алгоритм реализации МНК в Excel подразумевает, что все исходные данные уже известны. Обе части матричного уравнения AЧX=B системы умножаем слева на транспонированную матрицу системы А Т: А Т АХ=А Т В Затем обе части уравнения умножаем слева на матрицу (А Т А) -1 . Если эта матрица существует, то система определена. С учетом того, что (А Т А) -1 *(А Т А)=Е, получаем Х=(А Т А) -1 А Т В. Полученное матричное уравнение является решением системы m линейных уравнений с nнеизвестными при m>n. Рассмотрим применение вышеописанного алгоритма на конкретном примере. Пример. Пусть необходимо решить систему В Excelлист с решением в режиме отображения формул для данной задачи выглядит следующим образом: Результаты расчетов: Искомый вектор Х расположен в диапазоне Е11:Е12. При решении заданной системы линейных уравнений использовались следующие функции: 1. МОБР - возвращает обратную матрицу для матрицы, хранящейся в массиве. Синтаксис: МОБР(массив). Массив -- числовой массив с равным количеством строк и столбцов. 2. МУМНОЖ - возвращает произведение матриц (матрицы хранятся в массивах). Результатом является массив с таким же числом строк, как массив1 и с таким же числом столбцов, как массив2. Синтаксис: МУМНОЖ(массив1;массив2). Массив1, массив2 -- перемножаемые массивы. После введения функции в левую верхнюю ячейку диапазона массива следует выделить массив, начиная с ячейки, содержащей формулу, нажать клавишу F2, а затем нажать клавиши CTRL+SHIFT+ENTER. 3. ТРАНСП - преобразует вертикальный набор ячеек в горизонтальный, или наоборот. В результате использования этой функции появляется массив с числом строк, равным числу столбцов исходного массива, и числом столбцов, равным числу строк начального массива. Которое находит самое широкое применение в различных областях науки и практической деятельности. Это может быть физика, химия, биология, экономика, социология, психология и так далее, так далее. Волею судьбы мне часто приходится иметь дело с экономикой, и поэтому сегодня я оформлю вам путёвку в удивительную страну под названием Эконометрика
=) …Как это не хотите?! Там очень хорошо – нужно только решиться! …Но вот то, что вы, наверное, определённо хотите – так это научиться решать задачи методом наименьших квадратов
. И особо прилежные читатели научатся решать их не только безошибочно, но ещё и ОЧЕНЬ БЫСТРО;-) Но сначала общая постановка задачи
+ сопутствующий пример: Пусть в некоторой предметной области исследуются показатели , которые имеют количественное выражение. При этом есть все основания полагать, что показатель зависит от показателя . Это полагание может быть как научной гипотезой, так и основываться на элементарном здравом смысле. Оставим, однако, науку в сторонке и исследуем более аппетитные области – а именно, продовольственные магазины. Обозначим через: – торговую площадь продовольственного магазина, кв.м., Совершенно понятно, что чем больше площадь магазина, тем в большинстве случаев будет больше его товарооборот. Предположим, что после проведения наблюдений/опытов/подсчётов/танцев с бубном в нашем распоряжении оказываются числовые данные: Табличные данные также можно записать в виде точек и изобразить в привычной для нас декартовой системе
. Ответим на важный вопрос: сколько точек нужно для качественного исследования?
Чем больше, тем лучше. Минимально допустимый набор состоит из 5-6 точек. Кроме того, при небольшом количестве данных в выборку нельзя включать «аномальные» результаты. Так, например, небольшой элитный магазин может выручать на порядки больше «своих коллег», искажая тем самым общую закономерность, которую и требуется найти! Если совсем просто – нам нужно подобрать функцию , график
которой проходит как можно ближе к точкам Таким образом, разыскиваемая функция должна быть достаточно простА и в то же время отражать зависимость адекватно. Как вы догадываетесь, один из методов нахождения таких функций и называется методом наименьших квадратов
. Сначала разберём его суть в общем виде. Пусть некоторая функция приближает экспериментальные данные : Приближая экспериментальные точки различными функциями, мы будем получать разные значения , и очевидно, где эта сумма меньше – та функция и точнее. Такой метод существует и называется он методом наименьших модулей
. Однако на практике получил гораздо бОльшее распространение метод наименьших квадратов
, в котором возможные отрицательные значения ликвидируются не модулем, а возведением отклонений в квадрат: И сейчас мы возвращаемся к другому важному моменту: как отмечалось выше, подбираемая функция должна быть достаточно простА – но ведь и таких функций тоже немало: линейная
, гиперболическая
, экспоненциальная
, логарифмическая
, квадратичная
и т.д. И, конечно же, тут сразу бы хотелось «сократить поле деятельности». Какой класс функций выбрать для исследования? Примитивный, но эффективный приём: – Проще всего изобразить точки Если же точки расположены, например, по гиперболе
, то заведомо понятно, что линейная функция будет давать плохое приближение. В этом случае ищем наиболее «выгодные» коэффициенты для уравнения гиперболы А теперь обратите внимание, что в обоих случаях речь идёт о функции двух переменных
, аргументами которой являются параметры разыскиваемых зависимостей
: И по существу нам требуется решить стандартную задачу – найти минимум функции двух переменных
. Вспомним про наш пример: предположим, что «магазинные» точки имеют тенденцию располагаться по прямой линии и есть все основания полагать наличие линейной зависимости
товарооборота от торговой площади. Найдём ТАКИЕ коэффициенты «а» и «бэ», чтобы сумма квадратов отклонений Если хотите использовать данную информацию для реферата или курсовика – буду очень благодарен за поставленную ссылку в списке источников, такие подробные выкладки найдёте мало где: Составим стандартную систему: Сокращаем каждое уравнение на «двойку» и, кроме того, «разваливаем» суммы: Примечание
: самостоятельно проанализируйте, почему «а» и «бэ» можно вынести за значок суммы. Кстати, формально это можно проделать и с суммой
Перепишем систему в «прикладном» виде: Координаты точек мы знаем? Знаем. Суммы Функция Рассматриваемая задача имеет большое практическое значение. В ситуации с нашим примером, уравнение Я разберу всего лишь одну задачу с «реальными» числами, поскольку никаких трудностей в ней нет – все вычисления на уровне школьной программы 7-8 класса. В 95 процентов случаев вам будет предложено отыскать как раз линейную функцию, но в самом конце статьи я покажу, что ничуть не сложнее отыскать уравнения оптимальной гиперболы, экспоненты и некоторых других функций. По сути, осталось раздать обещанные плюшки – чтобы вы научились решать такие примеры не только безошибочно, но ещё и быстро. Внимательно изучаем стандарт: Задача
В результате исследования взаимосвязи двух показателей, получены следующие пары чисел: Заметьте, что «иксовые» значения – натуральные, и это имеет характерный содержательный смысл, о котором я расскажу чуть позже; но они, разумеется, могут быть и дробными. Кроме того, в зависимости от содержания той или иной задачи как «иксовые», так и «игрековые» значения полностью или частично могут быть отрицательными. Ну а у нас дана «безликая» задача, и мы начинаем её решение
: Коэффициенты оптимальной функции найдём как решение системы: В целях более компактной записи переменную-«счётчик» можно опустить, поскольку и так понятно, что суммирование осуществляется от 1 до . Расчёт нужных сумм удобнее оформить в табличном виде:
Таким образом, получаем следующую систему
: Тут можно умножить второе уравнение на 3 и из 1-го уравнения почленно вычесть 2-е
. Но это везение – на практике системы чаще не подарочны, и в таких случаях спасает метод Крамера
: Выполним проверку. Понимаю, что не хочется, но зачем же пропускать ошибки там, где их можно стопроцентно не пропустить? Подставим найденное решение в левую часть каждого уравнения системы: Таким образом, искомая аппроксимирующая функция: – из всех линейных функций
экспериментальные данные наилучшим образом приближает именно она. В отличие от прямой
зависимости товарооборота магазина от его площади, найденная зависимость является обратной
(принцип «чем больше – тем меньше»)
, и этот факт сразу выявляется по отрицательному угловому коэффициенту
. Функция Для построения графика аппроксимирующей функции найдём два её значения: и выполним чертёж: Вычислим сумму квадратов отклонений Вычисления сведём в таблицу:
Еще раз повторим: в чём смысл полученного результата?
Из всех линейных функций
у функции Найдем соответствующую сумму квадратов отклонений – чтобы различать, я обозначу их буквой «эпсилон». Техника точно такая же: Вывод
: , значит, экспоненциальная функция приближает экспериментальные точки хуже, чем прямая Но тут следует отметить, что «хуже» – это ещё не значит
, что плохо. Сейчас построил график этой экспоненциальной функции – и он тоже проходит близко к точкам На этом решение закончено, и я возвращаюсь к вопросу о натуральных значениях аргумента. В различных исследованиях, как правило, экономических или социологических, натуральными «иксами» нумеруют месяцы, годы или иные равные временнЫе промежутки. Рассмотрим, например, такую задачу. Ну вот, на работе перед инспекцией отчитались, статья дома для конференции написана — можно теперь и в блог писать. Пока данные свои обрабатывал, понял, что не могу не написать про очень классную и нужную надстройку в Excel, которая называется . Так что статья будет посвящена именно этой надстройке, и расскажу я о ней на примере использования метода наименьших квадратов
(МНК) для поиска неизвестных коэффициентов уравнения при описании экспериментальных данных. Как включить надстройку «поиск решения» Для начала разберемся, как эту надстройку включить. 1. Идем в меню «Файл» и выбираем пункт «Параметры Excel» 2. В появившемся окне выбираем «Поиск решения» и нажимаем «перейти». 3. В следующем окне ставим галочку напротив пункта «поиск решения» и нажимаем «ОК». 4. Надстройка активирована — теперь ее можно найти в пункте меню «Данные». Теперь вкратце о методе наименьших квадратов (МНК)
и о том, где его можно применять. Допустим, у нас есть набор данных после совершения нами какого-то эксперимента, где мы изучали влияния величины Х на величину Y. Мы хотим это влияние описать математически, чтобы потом этой формулой пользоваться и знать, что, если мы поменяем величину Х на столько-то, получим величину Y такую-то... Возьму супер-простой пример (см. рис.). Ежу понятно, что точки расположились друг за другом как будто по прямой, а потому мы смело предполагаем, что наша зависимость описывается линейной функцией y=kx+b. При этом мы точно уверены, что при X равном нулю значение Y тоже равно нулю. Значит, функция, описывающая зависимость, будет еще проще: y=kx (вспоминаем школьную программу). В общем, нам предстоит найти коэффициент k. Вот это мы и сделаем с помощью МНК
с применением надстройки «поиск решения». Метод заключается в том, чтобы (здесь — внимание: нужно вдуматься) сумма квадратов разностей экспериментально полученных и соответствующих расчетных значений была минимальной. То есть когда X1=1 реально измеренное значение Y1=4,6, а расчетное y1=f (x1) равно 4, квадрат разности будет (y1-Y1)^2=(4-4,6)^2=0,36. Со следующими так же: когда X2=2, реально измеренное значение Y2=8,1, а расчетное у2 равно 8, квадрат разности будет (y2-Y2)^2=(8-8,1)^2=0,01. И сумма всех этих квадратов должна быть минимально возможной. Итак, приступим к тренировке по использованию МНК и надстройки Excel «поиск решения»
. 1. Если не включили надстройку «поиск решения», то возвращаемся к пункту Как включить надстройку «поиск решения» и включаем
🙂 2. В ячейку А1 введем значение «1». Эта единица будет первым приближением к реальному значению коэффициента (k) нашей функциональной зависимости y=kx. 3. В столбце B у нас расположились значения параметра X, в столбце C — значения параметра Y. В ячейках столбца D вводим формулу: «коэффициент k умножить на значение Х». Например, в ячейке D1 вводим «=A1*B1», в ячейке D2 вводим "=A1*B2" и т.д. 4. Мы считаем, что коэффициент к равен единице и функция f (x)=у=1*х – это первое приближение к нашему решению. Можем рассчитать сумму квадратов разностей между измеренными значениями величины Y и рассчитанными по формуле y=1*х. Можем все это сделать вручную, вбивая в формулу соответствующие ссылки на ячейки: "=(D2-C2)^2+(D3-C3)^2+(D4-C4)^2... и т.д. В конце концов ошибаемся и понимаем, что потеряли кучу времени. В Excel для расчета суммы квадратов разностей есть специальная формула, «СУММКВРАЗН», которая все за нас и сделает. Введем ее в ячейку А2 и зададим исходные данные: диапазон измеренных значений Y (столбец C) и диапазон рассчитанных значений Y (столбец D). 4. Сумму разностей квадратов рассчитали – теперь идем во вкладку «Данные» и выбираем «Поиск решения». 5. В появившемся меню в качестве изменяемой ячейки выбираем ячейку A1 (та, что с коэффициентом k). 6. В качестве целевой выбираем ячейку A2 и задаем условие «установить равной минимальному значению». Помним, что это ячейка, где у нас производится расчёт суммы квадратов разностей расчетного и измеренного значений, и сумма эта должна быть минимальной. Нажимаем «выполнить». 7. Коэффициент k подобран. Теперь можно убедиться, что рассчитанные значения теперь очень близки к измеренным. Вообще, конечно, для аппроксимации экспериментальных данных в Excel существуют специальные инструменты, которые позволяют осуществлять описание данных с помощью линейной, экспоненциальной, степенной и полиномиальной функцией, поэтому часто можно обойтись и без надстройки «поиск решения»
. Обо всех этих способах апппроксимации я рассказывал в своем , так что если интересно, — посмотрите. А вот когда дело касается какой-нибудь экзотической функции с одним неизвестным коэффициентом
или задач оптимизации, то здесь надстройка
как нельзя кстати. Надстройку «поиск решения»
можно использовать и для других задач, главное — понять суть: есть ячейка, где мы подбираем значение, а есть целевая ячейка, в которой задано условие для подбора неизвестного параметра.Алгебраический метод наименьших квадратов
Анализ данных эксперимента
![]()

![]()
![]()

МНК в Excel



– годовой товарооборот продовольственного магазина, млн. руб.
С гастрономами, думаю, всё понятно: – это площадь 1-го магазина, – его годовой товарооборот, – площадь 2-го магазина, – его годовой товарооборот и т.д. Кстати, совсем не обязательно иметь доступ к секретным материалам – довольно точную оценку товарооборота можно получить средствами математической статистики
. Впрочем, не отвлекаемся, курс коммерческого шпионажа – он уже платный =)![]() . Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
. Такую функцию называют аппроксимирующей
(аппроксимация – приближение)
или теоретической функцией
. Вообще говоря, тут сразу появляется очевидный «претендент» – многочлен высокой степени, график которого проходит через ВСЕ точки. Но этот вариант сложен, а зачастую и просто некорректен (т.к. график будет всё время «петлять» и плохо отражать главную тенденцию)
.
Как оценить точность данного приближения? Вычислим и разности (отклонения) между экспериментальными и функциональными значениями (изучаем чертёж)
. Первая мысль, которая приходит в голову – это оценить, насколько великА сумма , но проблема состоит в том, что разности могут быть и отрицательны (например, ![]() )
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:
)
и отклонения в результате такого суммирования будут взаимоуничтожаться. Поэтому в качестве оценки точности приближения напрашивается принять сумму модулей
отклонений:![]() или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.
или в свёрнутом виде: (вдруг кто не знает: – это значок суммы, а – вспомогательная переменная-«счётчик», которая принимает значения от 1 до )
.![]() , после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений
, после чего усилия направлены на подбор такой функции , чтобы сумма квадратов отклонений ![]() была как можно меньше. Собственно, отсюда и название метода.
была как можно меньше. Собственно, отсюда и название метода.![]() на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
на чертеже и проанализировать их расположение. Если они имеют тенденцию располагаться по прямой, то следует искать уравнение прямой
![]() с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.
с оптимальными значениями и . Иными словами, задача состоит в нахождении ТАКИХ коэффициентов – чтобы сумма квадратов отклонений была наименьшей.![]() – те, которые дают минимальную сумму квадратов
– те, которые дают минимальную сумму квадратов  .
.
![]() была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:
была наименьшей. Всё как обычно – сначала частные производные 1-го порядка
. Согласно правилу линейности
дифференцировать можно прямо под значком суммы:



![]()

после чего начинает прорисовываться алгоритм решения нашей задачи:![]() найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция
найти можем? Легко. Составляем простейшую систему двух линейных уравнений с двумя неизвестными
(«а» и «бэ»). Систему решаем, например, методом Крамера
, в результате чего получаем стационарную точку . Проверяя достаточное условие экстремума
, можно убедиться, что в данной точке функция ![]() достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:
достигает именно минимума
. Проверка сопряжена с дополнительными выкладками и поэтому оставим её за кадром (при необходимости недостающий кадр можно посмотреть )
. Делаем окончательный вывод:![]() наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки
наилучшим образом (по крайне мере, по сравнению с любой другой линейной функцией)
приближает экспериментальные точки ![]() . Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.
. Грубо говоря, её график проходит максимально близко к этим точкам. В традициях эконометрики
полученную аппроксимирующую функцию также называют уравнением пАрной линейной регрессии
.![]() позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
позволяет прогнозировать, какой товарооборот («игрек»)
будет у магазина при том или ином значении торговой площади (том или ином значении «икс»)
. Да, полученный прогноз будет лишь прогнозом, но во многих случаях он окажется достаточно точным.
Методом наименьших квадратов найти линейную функцию, которая наилучшим образом приближает эмпирические (опытные)
данные. Сделать чертеж, на котором в декартовой прямоугольной системе координат построить экспериментальные точки и график аппроксимирующей функции ![]() . Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.
. Найти сумму квадратов отклонений между эмпирическими и теоретическими значениями. Выяснить, будет ли функция лучше (с точки зрения метода наименьших квадратов)
приближать экспериментальные точки.

Вычисления можно провести на микрокалькуляторе, но гораздо лучше использовать Эксель – и быстрее, и без ошибок; смотрим короткий видеоролик:![]()
, значит, система имеет единственное решение.
Получены правые части соответствующих уравнений, значит, система решена правильно.![]() сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
сообщает нам о том, что с увеличение некоего показателя на 1 единицу значение зависимого показателя уменьшается в среднем
на 0,65 единиц. Как говорится, чем выше цена на гречку, тем меньше её продано.
Построенная прямая называется линией тренда
(а именно – линией линейного тренда, т.е. в общем случае тренд – это не обязательно прямая линия)
. Всем знакомо выражение «быть в тренде», и, думаю, что этот термин не нуждается в дополнительных комментариях.![]() между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
между эмпирическими и теоретическими значениями. Геометрически – это сумма квадратов длин «малиновых» отрезков (два из которых настолько малы, что их даже не видно)
.
Их можно опять же провести вручную, на всякий случай приведу пример для 1-й точки:![]()
но намного эффективнее поступить уже известным образом:![]() показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция
показатель является наименьшим, то есть в своём семействе это наилучшее приближение. И здесь, кстати, не случаен заключительный вопрос задачи: а вдруг предложенная экспоненциальная функция ![]() будет лучше приближать экспериментальные точки?
будет лучше приближать экспериментальные точки?
И снова на всякий пожарный вычисления для 1-й точки:
В Экселе пользуемся стандартной функцией EXP
(синтаксис можно посмотреть в экселевской Справке)
.![]() .
.![]() – да так, что без аналитического исследования и сказать трудно, какая функция точнее.
– да так, что без аналитического исследования и сказать трудно, какая функция точнее.

Метод наименьших квадратов


Применение надстройки поиск решения



P.S.
Вот и все! В следующей статье расскажу сказку про отпуск, так что, чтобы не проворонить выход статьи,





