Matematické očakávanie binomického rozdelenia. Binomické rozdelenie náhodnej premennej. Vlastnosti binomického rozdelenia
Samozrejme, pri výpočte funkcie kumulatívneho rozdelenia by ste mali použiť spomínané spojenie medzi binomickým a beta rozdelením. Táto metóda je samozrejme lepšia ako priamy súčet, keď n > 10.
V klasických učebniciach štatistiky sa na získanie hodnôt binomického rozdelenia často odporúča používať vzorce založené na limitných vetách (ako je Moivre-Laplaceov vzorec). Treba poznamenať, že z čisto výpočtového hľadiska hodnota týchto teorémov je blízka nule, najmä teraz, keď takmer každý stôl má výkonný počítač. Hlavnou nevýhodou vyššie uvedených aproximácií je ich úplne nedostatočná presnosť pre hodnoty n charakteristické pre väčšinu aplikácií. Nemenej nevýhodou je absencia akýchkoľvek jasných odporúčaní o použiteľnosti tej či onej aproximácie (iba v štandardných textoch asymptotické formulácie nie sú sprevádzané odhadmi presnosti, a preto sú málo použiteľné). Povedal by som, že oba vzorce sú vhodné len pre n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Neberiem tu do úvahy problém hľadania kvantilov: pre diskrétne rozdelenia je to triviálne a v tých problémoch, kde takéto rozdelenia vznikajú, to spravidla nie je relevantné. Ak sú stále potrebné kvantily, odporúčam preformulovať problém tak, aby sa pracovalo s p-hodnotami (pozorované významy). Tu je príklad: pri implementácii niektorých vyčerpávajúcich vyhľadávacích algoritmov je v každom kroku potrebné otestovať štatistickú hypotézu o binomickej náhodnej premennej. Podľa klasického prístupu je potrebné v každom kroku vypočítať štatistiku kritéria a porovnať jej hodnotu s hranicou kritického súboru. Keďže je však algoritmus vyčerpávajúci, je potrebné určiť hranicu kritickej množiny zakaždým nanovo (veľkosť vzorky sa napokon mení z kroku na krok), čo neproduktívne zvyšuje časové náklady. Moderný prístup odporúča vypočítať pozorovanú významnosť a porovnať ju s pravdepodobnosťou spoľahlivosti, čím sa ušetrí na hľadaní kvantilov.
Preto v nižšie uvedených kódoch nie je výpočet inverznej funkcie, namiesto toho je uvedená funkcia rev_binomialDF, ktorá vypočíta pravdepodobnosť p úspechu v individuálnom pokuse pri danom počte pokusov n, počte m úspechov v nich a hodnotu y pravdepodobnosti získania týchto m úspechov. Toto využíva vyššie uvedené spojenie medzi binomickou a beta distribúciou.
V skutočnosti vám táto funkcia umožňuje získať hranice intervalov spoľahlivosti. Predpokladajme, že v n binomických pokusoch máme m úspechov. Ako je známe, ľavá hranica obojstranného intervalu spoľahlivosti pre parameter p s úrovňou spoľahlivosti sa rovná 0, ak m = 0, a pre je riešením rovnice  . Podobne pravá hranica je 1, ak m = n, a for je riešením rovnice
. Podobne pravá hranica je 1, ak m = n, a for je riešením rovnice  . Z toho vyplýva, že na nájdenie ľavej hranice musíme vyriešiť relatívnu rovnicu
. Z toho vyplýva, že na nájdenie ľavej hranice musíme vyriešiť relatívnu rovnicu  a nájsť tú správnu – rovnicu
a nájsť tú správnu – rovnicu  . Riešia sa vo funkciách binom_leftCI a binom_rightCI, ktoré vracajú hornú a dolnú hranicu obojstranného intervalu spoľahlivosti.
. Riešia sa vo funkciách binom_leftCI a binom_rightCI, ktoré vracajú hornú a dolnú hranicu obojstranného intervalu spoľahlivosti.
Chcel by som poznamenať, že ak nepotrebujete absolútne neuveriteľnú presnosť, potom pre dostatočne veľké n môžete použiť nasledujúcu aproximáciu [B.L. van der Waerden, Matematická štatistika. M: IL, 1960, kap. 2, oddiel 7]:  , kde g je kvantil normálneho rozdelenia. Hodnota tejto aproximácie spočíva v tom, že existujú veľmi jednoduché aproximácie, ktoré vám umožňujú vypočítať kvantily normálneho rozdelenia (pozri text o výpočte normálneho rozdelenia a zodpovedajúcu časť tejto príručky). V mojej praxi (hlavne s n > 100) táto aproximácia dávala približne 3-4 číslice, čo je spravidla dosť.
, kde g je kvantil normálneho rozdelenia. Hodnota tejto aproximácie spočíva v tom, že existujú veľmi jednoduché aproximácie, ktoré vám umožňujú vypočítať kvantily normálneho rozdelenia (pozri text o výpočte normálneho rozdelenia a zodpovedajúcu časť tejto príručky). V mojej praxi (hlavne s n > 100) táto aproximácia dávala približne 3-4 číslice, čo je spravidla dosť.
Na výpočet pomocou nasledujúcich kódov budete potrebovať súbory betaDF.h, betaDF.cpp (pozri časť o beta distribúcii), ako aj logGamma.h, logGamma.cpp (pozri Prílohu A). Môžete vidieť aj príklad použitia funkcií.
Súbor binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(dvojité pokusy, dvojité úspechy, dvojité p); /* * Nech sú "skúšky" nezávislých pozorovaní * s pravdepodobnosťou "p" úspechu v každom. * Vypočítajte pravdepodobnosť B(úspechy|skúšky,p), že počet * úspechov leží medzi 0 a "úspechmi" (vrátane). */ double rev_binomialDF(dvojité pokusy, dvojité úspechy, dvojité y); /* * Nech je známa pravdepodobnosť y aspoň m úspechov * v pokusoch testujúcich Bernoulliho schému. Funkcia nájde pravdepodobnosť p* úspechu v individuálnom pokuse. * * Vo výpočtoch sa používa nasledujúci vzťah * * 1 - p = rev_Beta(pokusy-úspechy| úspechy+1, y). */ double binom_leftCI(dvojité pokusy, dvojité úspechy, dvojitá úroveň); /* Nech sú "skúšky" nezávislých pozorovaní * s pravdepodobnosťou "p" úspechu v každom * a počtom úspechov rovným "úspechov". * Ľavá hranica obojstranného intervalu spoľahlivosti sa vypočíta * s hladinou významnosti. */ double binom_rightCI(dvojité n, dvojité úspechy, dvojitá úroveň); /* Nech sú "skúšky" nezávislých pozorovaní * s pravdepodobnosťou "p" úspechu v každom * a počtom úspechov rovným "úspechov". * Pravá hranica obojstranného intervalu spoľahlivosti sa vypočíta * s hladinou významnosti. */ #endif /* Končí #ifndef __BINOMIAL_H__ */ |
Súbor binomialDF.cpp
| /******************************************************* * ********/ /* Binomické rozdelenie */ /********************************** * *****************************/ #include |
Teória pravdepodobnosti je v našich životoch neviditeľne prítomná. Nevenujeme tomu pozornosť, ale každá udalosť v našom živote má jednu alebo druhú pravdepodobnosť. Berúc do úvahy obrovské množstvo možných scenárov, je pre nás nevyhnutné určiť najpravdepodobnejší a najmenej pravdepodobný z nich. Najpohodlnejšie je analyzovať takéto pravdepodobnostné údaje graficky. V tomto nám môže pomôcť distribúcia. Binomický je jedným z najjednoduchších a najpresnejších.
Skôr než prejdeme priamo k matematike a teórii pravdepodobnosti, poďme zistiť, kto ako prvý prišiel s týmto typom rozdelenia a aká je história vývoja matematického aparátu pre tento koncept.
Príbeh
Pojem pravdepodobnosti je známy už od staroveku. Starovekí matematici tomu však neprikladali veľký význam a dokázali len položiť základy teórie, ktorá sa neskôr stala teóriou pravdepodobnosti. Vytvorili niekoľko kombinatorických metód, ktoré veľmi pomohli tým, ktorí neskôr vytvorili a rozvíjali samotnú teóriu.
V druhej polovici 17. storočia sa začali formovať základné pojmy a metódy teórie pravdepodobnosti. Boli zavedené definície náhodných veličín a metódy výpočtu pravdepodobnosti jednoduchých a niektorých zložitých nezávislých a závislých udalostí. Tento záujem o náhodné premenné a pravdepodobnosti bol diktovaný hazardom: každý chcel vedieť, aké sú jeho šance na výhru v hre.
Ďalšou etapou bola aplikácia metód matematickej analýzy v teórii pravdepodobnosti. Tejto úlohy sa ujali významní matematici ako Laplace, Gauss, Poisson a Bernoulli. Boli to oni, ktorí posunuli túto oblasť matematiky na novú úroveň. Bol to James Bernoulli, kto objavil zákon binomického rozdelenia. Mimochodom, ako sa neskôr dozvieme, na základe tohto objavu bolo urobených niekoľko ďalších, čo umožnilo vytvoriť zákon normálneho rozdelenia a mnohé ďalšie.
Teraz, skôr ako začneme opisovať binomické rozdelenie, si trochu osviežime pamäť na pojmy teórie pravdepodobnosti, ktoré sme už zrejme zabudli zo školy.
Základy teórie pravdepodobnosti
Budeme zvažovať také systémy, v dôsledku ktorých sú možné len dva výsledky: „úspech“ a „neúspech“. To je ľahko pochopiteľné na príklade: hodíme si mincou v nádeji, že sa nám to podarí. Pravdepodobnosť každej z možných udalostí (padanie hláv – „úspech“, padanie hláv – „neúspech“) sa rovná 50 percentám, ak je minca dokonale vyvážená a neexistujú žiadne ďalšie faktory, ktoré môžu experiment ovplyvniť.
Bola to najjednoduchšia udalosť. Existujú však aj zložité systémy, v ktorých sa vykonávajú sekvenčné akcie a pravdepodobnosti výsledkov týchto akcií sa budú líšiť. Uvažujme napríklad o nasledujúcom systéme: v krabici, ktorej obsah nevidíme, je šesť úplne rovnakých loptičiek, tri páry modrej, červenej a biele kvety. Musíme získať niekoľko loptičiek náhodne. V súlade s tým tým, že najprv vytiahneme jednu z bielych guľôčok, výrazne znížime pravdepodobnosť, že nabudúce získame aj bielu guľôčku. Stáva sa to preto, že počet objektov v systéme sa mení.
V ďalšej časti sa pozrieme na zložitejšie matematické pojmy, ktoré nám priblížia, čo znamenajú slová „normálne rozdelenie“, „binomické rozdelenie“ a podobne.

Prvky matematickej štatistiky
V štatistike, ktorá je jednou z oblastí aplikácie teórie pravdepodobnosti, existuje veľa príkladov, kde nie sú explicitne uvedené údaje na analýzu. Teda nie číselne, ale formou delenia podľa vlastností, napríklad podľa pohlavia. Aby bolo možné na takéto údaje aplikovať matematické nástroje a zo získaných výsledkov vyvodiť nejaké závery, je potrebné previesť pôvodné údaje do číselného formátu. Zvyčajne sa na tento účel pozitívnemu výsledku priradí hodnota 1 a negatívnemu výsledku sa priradí hodnota 0. Takto získame štatistické údaje, ktoré možno analyzovať pomocou matematických metód.
Ďalším krokom k pochopeniu toho, čo je binomické rozdelenie náhodná premenná, je definícia rozptylu náhodnej premennej a matematického očakávania. O tom si povieme v ďalšej časti.

Očakávaná hodnota
Naozaj pochopiť, čo to je očakávaná hodnota, nenáročný. Uvažujme o systéme, v ktorom existuje veľa rôznych udalostí s vlastnými rôznymi pravdepodobnosťami. Matematické očakávanie sa bude nazývať hodnota rovnajúca sa súčtu súčinov hodnôt týchto udalostí (v matematickej forme, o ktorej sme hovorili v poslednej časti) a pravdepodobnosti ich výskytu.
Matematické očakávanie binomického rozdelenia sa vypočíta pomocou rovnakej schémy: vezmeme hodnotu náhodnej premennej, vynásobíme ju pravdepodobnosťou pozitívneho výsledku a potom spočítame výsledné údaje pre všetky premenné. Je veľmi výhodné prezentovať tieto údaje graficky - takto je lepšie vnímaný rozdiel medzi matematickými očakávaniami rôznych hodnôt.
V ďalšej časti si povieme niečo o ďalšom koncepte – rozptyl náhodnej premennej. Úzko súvisí aj s konceptom binomického rozdelenia pravdepodobnosti a je jeho charakteristikou.

Rozptyl binomického rozdelenia
Táto hodnota úzko súvisí s predchádzajúcou a charakterizuje aj rozdelenie štatistických údajov. Predstavuje priemerný štvorec odchýlok hodnôt od ich matematického očakávania. To znamená, že rozptyl náhodnej premennej je súčet štvorcových rozdielov medzi hodnotou náhodnej premennej a jej matematickým očakávaním, vynásobený pravdepodobnosťou tejto udalosti.
Vo všeobecnosti je to všetko, čo potrebujeme vedieť o rozptyle, aby sme pochopili, čo je binomické rozdelenie pravdepodobnosti. Teraz prejdime priamo k našej hlavnej téme. Konkrétne, čo sa skrýva za takouto zdanlivo pomerne zložitou frázou „zákon o binomickom rozdelení“.

Binomické rozdelenie
Poďme najprv zistiť, prečo je toto rozdelenie binomické. Pochádza zo slova „binom“. Možno ste už počuli o Newtonovom binome – vzorci, ktorý možno použiť na rozšírenie súčtu ľubovoľných dvoch čísel a a b na ľubovoľnú nezápornú mocninu n.
Ako ste už pravdepodobne uhádli, Newtonov binomický vzorec a vzorec binomického rozdelenia sú takmer rovnaké vzorce. S jedinou výnimkou, že druhý má praktický význam pre konkrétne veličiny a prvý je len všeobecným matematickým nástrojom, ktorého aplikácie v praxi môžu byť rôzne.
Distribučné vzorce
Funkciu binomického rozdelenia možno zapísať ako súčet nasledujúcich výrazov:
(n!/(n-k)!k!)*p k *q n-k
Tu n je počet nezávislých náhodných experimentov, p je počet úspešných výsledkov, q je počet neúspešných výsledkov, k je číslo experimentu (môže nadobúdať hodnoty od 0 do n),! - označenie faktoriálu, funkcie čísla, ktorého hodnota sa rovná súčinu všetkých čísel pred ním (napr. pre číslo 4: 4!=1*2*3*4=24).
Okrem toho možno funkciu binomického rozdelenia zapísať ako neúplnú funkciu beta. Ide však o komplexnejšiu definíciu, ktorá sa používa len pri riešení zložitých štatistických problémov.
Binomické rozdelenie, príklady, na ktoré sme sa pozreli vyššie, je jedným z najviac jednoduché typy distribúcie v teórii pravdepodobnosti. Existuje aj normálne rozdelenie, čo je typ binomického celku. Používa sa najčastejšie a najľahšie sa počíta. Existujú tiež Bernoulliho distribúcie, Poissonove distribúcie a podmienené distribúcie. Všetky graficky charakterizujú rozsahy pravdepodobnosti konkrétneho procesu za rôznych podmienok.
V ďalšej časti zvážime aspekty súvisiace s používaním tohto matematického aparátu v skutočný život. Na prvý pohľad sa samozrejme zdá, že ide len o ďalšiu matematickú vec, ktorá, ako to už býva, v reálnom živote nenájde uplatnenie a okrem samotných matematikov ju vo všeobecnosti nikto nepotrebuje. Nie je to však tak. Koniec koncov, všetky typy distribúcií a ich grafické znázornenia boli vytvorené výlučne na praktické účely, a nie z rozmaru vedcov.

Aplikácia
Najdôležitejšie uplatnenie distribúcií je samozrejme v štatistike, pretože vyžadujú komplexnú analýzu mnohých údajov. Ako ukazuje prax, mnohé súbory údajov majú približne rovnaké rozloženie hodnôt: kritické oblasti veľmi nízkych a veľmi vysokých hodnôt spravidla obsahujú menej prvkov ako priemerné hodnoty.
Analýza veľkých súborov údajov je potrebná nielen v štatistike. Je nepostrádateľný napríklad vo fyzikálnej chémii. V tejto vede sa používa na určenie mnohých veličín, ktoré sú spojené s náhodnými vibráciami a pohybmi atómov a molekúl.
V ďalšej časti pochopíme, aké dôležité je používať štatistické pojmy, ako je binomický rozdelenie náhodnej premennej v každodennom živote pre vás a mňa.

Prečo to potrebujem?
Túto otázku si kladie veľa ľudí, keď príde reč na matematiku. Mimochodom, nie nadarmo sa matematike hovorí kráľovná vied. Je základom fyziky, chémie, biológie, ekonómie a v každej z týchto vied sa používa aj nejaké rozdelenie: či ide o diskrétne binomické rozdelenie alebo o normálne, na tom nezáleží. A ak sa bližšie pozrieme na svet okolo nás, uvidíme, že matematika sa používa všade: v každodennom živote, v práci a dokonca aj medziľudské vzťahy môžu byť reprezentované vo forme štatistických údajov a analyzované (mimochodom , je to, čo tí, ktorí pracujú v špeciálnych organizáciách zapojených do zhromažďovania informácií).
Teraz si povedzme trochu o tom, čo robiť, ak potrebujete o tejto téme vedieť oveľa viac, ako sme načrtli v tomto článku.
Informácie, ktoré sme uviedli v tomto článku, nie sú ani zďaleka úplné. Existuje veľa nuancií, pokiaľ ide o formu, ktorú môže mať distribúcia. Binomické rozdelenie, ako sme už zistili, je jedným z hlavných typov, na ktorom sú založené všetky matematické štatistiky a teória pravdepodobnosti.
Ak vás zaujme, alebo v súvislosti s vašou prácou potrebujete vedieť o tejto téme oveľa viac, budete si musieť naštudovať odbornú literatúru. Mali by ste začať s univerzitným kurzom matematická analýza a dostať sa tam do časti o teórii pravdepodobnosti. Znalosť radov tiež príde vhod, pretože binomické rozdelenie pravdepodobnosti nie je nič iné ako séria po sebe nasledujúcich členov.
Záver
Pred dokončením článku by sme vám chceli povedať ešte jednu zaujímavosť. Týka sa to priamo témy nášho článku a vôbec celej matematiky.
Mnoho ľudí hovorí, že matematika je zbytočná veda a nič z toho, čo študovali v škole, im nebolo užitočné. Ale vedomosti nie sú nikdy zbytočné a ak vám niečo v živote nie je užitočné, znamená to, že si to jednoducho nepamätáte. Ak máte vedomosti, môžu vám pomôcť, ale ak nie, nemôžete od nich očakávať pomoc.
Pozreli sme sa teda na koncept binomického rozdelenia a všetky s ním spojené definície a hovorili sme o tom, ako sa používa v našich životoch.
Binomické rozdelenie je jedným z najdôležitejších rozdelení pravdepodobnosti diskrétne sa meniacej náhodnej premennej. Binomické rozdelenie je rozdelenie pravdepodobnosti čísla m výskyt udalosti A V n vzájomne nezávislé pozorovania. Často udalosť A sa nazýva „úspech“ pozorovania a opačná udalosť sa nazýva „zlyhanie“, ale toto označenie je veľmi podmienené.
Podmienky binomického rozdelenia:
- celkovo vykonaná n pokusy, v ktorých sa event A môže alebo nemusí nastať;
- udalosť A v každom pokuse môže nastať s rovnakou pravdepodobnosťou p;
- testy sú navzájom nezávislé.
Pravdepodobnosť, že v n testovacie podujatie A príde presne m krát, možno vypočítať pomocou Bernoulliho vzorca:
![]()
Kde p- pravdepodobnosť výskytu udalosti A;
q = 1 - p- pravdepodobnosť výskytu opačnej udalosti.
Poďme na to prečo binomické rozdelenie súvisí s Bernoulliho vzorcom spôsobom opísaným vyššie? . Udalosť – počet úspechov pri n testy sú rozdelené do niekoľkých možností, v každej z nich sa dosiahne úspech v m testy, a zlyhanie - v n - m testy. Zoberme si jednu z týchto možností - B1 . Pomocou pravidla na sčítanie pravdepodobností vynásobíme pravdepodobnosti opačných udalostí:
![]() ,
,
a ak označíme q = 1 - p, To
![]() .
.
Akákoľvek iná možnosť, v ktorej múspech a n - m zlyhania. Počet takýchto možností sa rovná počtu spôsobov, ktorými sa dá n test dostať múspech.
Súčet všetkých pravdepodobností mčísla výskytu udalostí A(čísla od 0 do n) sa rovná jednej:
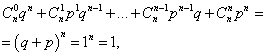
kde každý člen predstavuje člen v Newtonovom binome. Preto sa uvažované rozdelenie nazýva binomické rozdelenie.
V praxi je často potrebné vypočítať pravdepodobnosti „nie viac ako múspech v n testy“ alebo „aspoň múspech v n testy". Používajú sa na to nasledujúce vzorce.
Integrálna funkcia, tzn pravdepodobnosť F(m) čo je in n pozorovacia udalosť A viac nepríde m raz, možno vypočítať pomocou vzorca:
Vo svojom poradí pravdepodobnosť F(≥m) čo je in n pozorovacia udalosť A nepríde o nič menej m raz, sa vypočíta podľa vzorca:
Niekedy je vhodnejšie vypočítať pravdepodobnosť, že n pozorovacia udalosť A viac nepríde m krát, prostredníctvom pravdepodobnosti opačnej udalosti:
![]() .
.
Ktorý vzorec použiť, závisí od toho, ktorý z nich má súčet obsahujúci menej výrazov.
Charakteristiky binomického rozdelenia sa vypočítajú pomocou nasledujúcich vzorcov .
Očakávaná hodnota: .
Disperzia: .
Smerodajná odchýlka: .
Binomické rozdelenie a výpočty v MS Excel
Binomická pravdepodobnosť P n( m) a hodnoty integrálnej funkcie F(m) možno vypočítať pomocou funkcie MS Excel BINOM.DIST. Okno pre príslušný výpočet je zobrazené nižšie (kliknutím ľavým tlačidlom myši ho zväčšíte).

MS Excel vyžaduje, aby ste zadali nasledujúce údaje:
- počet úspechov;
- počet testov;
- pravdepodobnosť úspechu;
- integrál - logická hodnota: 0 - ak potrebujete vypočítať pravdepodobnosť P n( m) a 1 - ak je pravdepodobnosť F(m).
Príklad 1 Manažér spoločnosti zhrnul informácie o počte predaných kamier za posledných 100 dní. V tabuľke sú zhrnuté informácie a vypočítaná pravdepodobnosť, že sa za deň predá určitý počet kamier.
Deň končí ziskom, ak sa predá 13 a viac kamier. Pravdepodobnosť, že deň bude spracovaný so ziskom:
![]()
Pravdepodobnosť, že deň bude odpracovaný bez zisku:

Pravdepodobnosť, že sa deň odpracuje so ziskom, nech je konštantná a rovná sa 0,61 a počet predaných kamier za deň nezávisí od dňa. Potom môžeme použiť binomické rozdelenie, kde udalosť A- deň bude odpracovaný so ziskom, - bez zisku.
Pravdepodobnosť, že všetkých 6 dní bude vypracovaných so ziskom:
![]() .
.
Rovnaký výsledok dostaneme pomocou funkcie MS Excel BINOM.DIST (hodnota integrálu je 0):
P 6 (6 ) = BINOM.DIST(6; 6; 0,61; 0) = 0,052.
Pravdepodobnosť, že zo 6 dní budú 4 alebo viac dní odpracované so ziskom:
Kde ![]() ,
,
![]() ,
,
Pomocou funkcie MS Excel BINOM.DIST vypočítame pravdepodobnosť, že zo 6 dní nebudú viac ako 3 dni ukončené so ziskom (hodnota integrálnej hodnoty je 1):
P 6 (≤3 ) = BINOM.DIST(3; 6; 0,61; 1) = 0,435.
Pravdepodobnosť, že všetkých 6 dní bude vypracovaných so stratami:
![]() ,
,
Rovnaký ukazovateľ môžeme vypočítať pomocou funkcie MS Excel BINOM.DIST:
P 6 (0 ) = BINOM.DIST(0; 6; 0,61; 0) = 0,0035.
Vyriešte problém sami a potom uvidíte riešenie
Príklad 2 V urne sú 2 biele gule a 3 čierne gule. Z urny sa vyberie loptička, nastaví sa farba a vráti sa späť. Pokus sa opakuje 5-krát. Počet výskytov bielych guľôčok je diskrétna náhodná premenná X, rozdelené podľa binomického zákona. Zostavte zákon rozdelenia náhodnej premennej. Definujte mód, matematické očakávanie a disperziu.
Pokračujme v riešení problémov spoločne
Príklad 3 Od kuriérskej služby sme išli na stránky n= 5 kuriérov. Každý kuriér je pravdepodobný p= 0,3, bez ohľadu na ostatné, je pre objekt neskoro. Diskrétna náhodná premenná X- počet oneskorených kuriérov. Zostrojte distribučný rad pre túto náhodnú premennú. Nájdite jeho matematické očakávanie, rozptyl, smerodajnú odchýlku. Nájdite pravdepodobnosť, že aspoň dvaja kuriéri budú meškať pre predmety.
Kapitola 7.
Špecifické zákony rozdelenia náhodných veličín
Typy zákonov rozdelenia diskrétnych náhodných veličín
Nech diskrétna náhodná premenná nadobúda hodnoty X 1 , X 2 , …, x n,…. Pravdepodobnosti týchto hodnôt možno vypočítať pomocou rôznych vzorcov, napríklad pomocou základných teorémov teórie pravdepodobnosti, Bernoulliho vzorca alebo niektorých iných vzorcov. Pre niektoré z týchto vzorcov má zákon o rozdeľovaní svoj vlastný názov.
Najbežnejšie zákony rozdelenia diskrétnej náhodnej premennej sú binomický, geometrický, hypergeometrický a Poissonov zákon rozdelenia.
Zákon binomického rozdelenia
Nech sa vyrába n nezávislé pokusy, v každom z nich sa udalosť môže, ale nemusí objaviť A. Pravdepodobnosť výskytu tejto udalosti v každom jednotlivom pokuse je konštantná, nezávisí od počtu pokusov a rovná sa R=R(A). Z toho vyplýva pravdepodobnosť, že udalosť nenastane A v každom teste je tiež konštantný a rovnaký q=1–R. Zvážte náhodnú premennú X rovná počtu výskytov udalosti A V n testy. Je zrejmé, že hodnoty tohto množstva sú rovnaké
X 1 = 0 – udalosť A V n testy sa neobjavili;
X 2 = 1 – udalosť A V n objavil sa raz v súdnych procesoch;
X 3 =2 – udalosť A V n testy sa objavili dvakrát;
…………………………………………………………..
x n +1 = n- udalosť A V n všetko sa objavilo počas testov n raz.
Pravdepodobnosť týchto hodnôt je možné vypočítať pomocou Bernoulliho vzorca (4.1):
Kde Komu=0, 1, 2, …,n .
Zákon binomického rozdelenia X, ktorý sa rovná počtu úspechov v n Bernoulliho testy s pravdepodobnosťou úspechu R.
Diskrétna náhodná premenná má teda binomické rozdelenie (alebo je rozdelená podľa binomického zákona), ak jej možné hodnoty sú 0, 1, 2, ..., n a zodpovedajúce pravdepodobnosti sa vypočítajú pomocou vzorca (7.1).
Binomické rozdelenie závisí od dvoch parametre R A n.
Distribučný rad náhodnej premennej distribuovanej podľa binomického zákona má tvar:
| X | … | k | … | n | ||
| R | | … | … | |
Príklad 7.1 . Na cieľ sa strieľajú tri nezávislé výstrely. Pravdepodobnosť zásahu každého výstrelu je 0,4. Náhodná hodnota X– počet zásahov do cieľa. Zostavte jeho distribučnú sériu.
Riešenie. Možné hodnoty náhodnej premennej X sú X 1 =0; X 2 =1; X 3 =2; X 4 = 3. Nájdite zodpovedajúce pravdepodobnosti pomocou Bernoulliho vzorca. Nie je ťažké preukázať, že použitie tohto vzorca je tu úplne opodstatnené. Všimnite si, že pravdepodobnosť nezasiahnutia cieľa jednou ranou sa bude rovnať 1-0,4=0,6. Dostaneme

Distribučná séria má nasledujúcu formu:
| X | ||||
| R | 0,216 | 0,432 | 0,288 | 0,064 |
Je ľahké overiť, že súčet všetkých pravdepodobností je rovný 1. Samotná náhodná premenná X rozdelené podľa binomického zákona. ■
Nájdime matematické očakávanie a rozptyl náhodnej premennej rozloženej podľa binomického zákona.
Pri riešení príkladu 6.5 sa ukázalo, že matematické očakávanie počtu výskytov udalosti A V n nezávislých skúšok, ak je pravdepodobnosť výskytu A v každom teste je konštantná a rovnaká R, rovná sa n· R
V tomto príklade bola použitá náhodná premenná rozložená podľa binomického zákona. Preto je riešenie príkladu 6.5 v podstate dôkazom nasledujúcej vety.
Veta 7.1. Matematické očakávanie diskrétnej náhodnej premennej rozloženej podľa binomického zákona sa rovná súčinu počtu pokusov a pravdepodobnosti „úspechu“, t.j. M(X)=n· R.
Veta 7.2. Rozptyl diskrétnej náhodnej premennej rozloženej podľa binomického zákona sa rovná súčinu počtu pokusov pravdepodobnosti „úspechu“ a pravdepodobnosti „neúspechu“, t.j. D(X)=nрq.
Asymetria a špičatosť náhodnej premennej rozloženej podľa binomického zákona sú určené vzorcami
Tieto vzorce možno získať pomocou konceptu počiatočných a centrálnych momentov.
Zákon o binomickom rozdelení je základom mnohých reálnych situácií. o veľké hodnoty n Binomické rozdelenie možno aproximovať pomocou iných rozdelení, najmä Poissonovho rozdelenia.
Poissonovo rozdelenie
Nech je tam n Bernoulliho testy s počtom testov n dosť veľký. Už skôr sa ukázalo, že v tomto prípade (ak navyše pravdepodobnosť R diania A veľmi malá) nájsť pravdepodobnosť, že udalosť A objaviť sa T V testoch môžete použiť Poissonov vzorec (4.9). Ak náhodná premenná X znamená počet výskytov udalosti A V n Bernoulliho testy, potom pravdepodobnosť, že X nadobudne hodnotu k možno vypočítať pomocou vzorca
 , (7.2)
, (7.2)
Kde λ = č.
Poissonov zákon o rozdelení sa nazýva rozdelenie diskrétnej náhodnej premennej X, pre ktoré sú možnými hodnotami nezáporné celé čísla, a pravdepodobnosti r t tieto hodnoty sa zistia pomocou vzorca (7.2).
Rozsah λ = č volal parameter Poissonove distribúcie.
Náhodná premenná rozdelená podľa Poissonovho zákona môže nadobudnúť nekonečné množstvo hodnôt. Keďže pre toto rozdelenie je pravdepodobnosť R Výskyt udalosti v každom pokuse je malý, potom sa toto rozdelenie niekedy nazýva zákon zriedkavých udalostí.
Distribučný rad náhodnej premennej rozloženej podľa Poissonovho zákona má tvar
| X | … | T | … | ||||
| R | … | … |
Je ľahké overiť, že súčet pravdepodobností druhého radu je rovný 1. Aby ste to dosiahli, musíte si uvedomiť, že funkcia môže byť rozšírená do Maclaurinovho radu, ktorý konverguje pre ľubovoľné X. V tomto prípade máme
 . (7.3)
. (7.3)
Ako bolo uvedené, Poissonov zákon nahrádza v určitých obmedzujúcich prípadoch binomický zákon. Príkladom je náhodná premenná X, ktorých hodnoty sa rovnajú počtu porúch za určité časové obdobie pri opakovanom používaní technického prostriedku. Predpokladá sa, že ide o vysoko spoľahlivé zariadenie, t.j. Pravdepodobnosť zlyhania jednej aplikácie je veľmi malá.
Okrem takýchto limitujúcich prípadov v praxi existujú náhodné premenné rozdelené podľa Poissonovho zákona, ktoré nie sú spojené s binomickým rozdelením. Napríklad Poissonovo rozdelenie sa často používa pri riešení počtu udalostí vyskytujúcich sa v určitom časovom období (počet hovorov prijatých na telefónnej ústredni za hodinu, počet áut prichádzajúcich do autoumyvárne počas dňa, počet zastavení stroja za týždeň atď.). Všetky tieto udalosti by mali tvoriť takzvaný tok udalostí, čo je jeden zo základných konceptov teórie radenia. Parameter λ charakterizuje priemernú intenzitu toku udalostí.
Príklad 7.2 . Na fakulte je 500 študentov. Aká je pravdepodobnosť, že 1. septembra majú narodeniny traja študenti tohto odboru?
Riešenie . Od počtu žiakov n=500 je dosť veľký a R– pravdepodobnosť narodenia prvého septembra u niektorého zo žiakov sa rovná , t.j. je dostatočne malý, potom môžeme predpokladať, že náhodná premenná X– počet žiakov narodených 1. septembra je rozdelený podľa Poissonovho zákona s parametrom λ = n.p.= = 1,36986. Potom podľa vzorca (7.2) dostaneme
Veta 7.3. Nech náhodná premenná X distribuované podľa Poissonovho zákona. Potom sa jeho matematické očakávanie a rozptyl navzájom rovnajú a rovnajú sa hodnote parametra λ , t.j. M(X) = D(X) = λ = n.p..
Dôkaz. Definíciou matematického očakávania pomocou vzorca (7.3) a distribučného radu náhodnej premennej rozloženej podľa Poissonovho zákona dostaneme
Pred nájdením rozptylu najprv nájdeme matematické očakávanie druhej mocniny uvažovanej náhodnej premennej. Dostaneme

Odtiaľ, podľa definície disperzie, dostaneme
Veta je dokázaná.
Pomocou konceptov počiatočných a centrálnych momentov je možné ukázať, že pre náhodnú premennú distribuovanú podľa Poissonovho zákona sú koeficienty šikmosti a špičatosti určené vzorcami
Nie je ťažké to pochopiť, pretože sémantický obsah parametra λ = n.p. je kladná, potom náhodná premenná distribuovaná podľa Poissonovho zákona má vždy kladnú šikmosť a špičatosť.
Zoberme si binomické rozdelenie, vypočítajme jeho matematické očakávanie, rozptyl a režim. Pomocou funkcie MS EXCEL BINOM.DIST() vykreslíme grafy distribučnej funkcie a hustoty pravdepodobnosti. Odhadnime parameter rozdelenia p, matematické očakávanie rozdelenia a smerodajnú odchýlku. Zoberme si tiež Bernoulliho rozdelenie.
Definícia. Nech sa uskutočnia n pokusy, v každom z nich sa môžu vyskytnúť iba 2 udalosti: udalosť „úspech“ s pravdepodobnosťou p alebo „zlyhanie“ s pravdepodobnosťou q =1-p (tzv Bernoulliho schéma,Bernoulliskúšok).
Pravdepodobnosť presného prijatia X úspech v týchto n testy sa rovnajú:
Počet úspechov vo vzorke X je náhodná premenná, ktorá má Binomické rozdelenie(Angličtina) Binomickýdistribúcia) p A n – sú parametre tohto rozdelenia.
Nezabudnite to použiť Bernoulliho schémy a zodpovedajúcim spôsobom binomické rozdelenie, musia byť splnené tieto podmienky:
- Každý test musí mať presne dva výsledky, bežne nazývané „úspech“ a „neúspech“.
- výsledok každého testu by nemal závisieť od výsledkov predchádzajúcich testov (nezávislosť testu).
- pravdepodobnosť úspechu p musí byť konštantná pre všetky testy.
Binomická distribúcia v MS EXCEL
V MS EXCEL, počnúc verziou 2010, pre existuje funkcia BINOM.DIST(), anglický názov je BINOM.DIST(), ktorá umožňuje vypočítať pravdepodobnosť, že bude presne X"úspech" (t.j. funkcia hustoty pravdepodobnosti p(x), pozri vzorec vyššie) a kumulatívna distribučná funkcia(pravdepodobnosť, že vzorka bude mať X alebo menej „úspechov“ vrátane 0).
Pred MS EXCEL 2010 mal EXCEL funkciu BINOMIST(), ktorá tiež umožňuje vypočítať distribučná funkcia A hustota pravdepodobnosti p(x). BINOMIST() je ponechaný v MS EXCEL 2010 kvôli kompatibilite.
Vzorový súbor obsahuje grafy rozdelenie hustoty pravdepodobnosti A .

Binomické rozdelenie má označenie B (n ; p) .
Poznámka: Na stavbu kumulatívna distribučná funkcia perfektný typový diagram Rozvrh, Pre hustota distribúcie – Histogram so zoskupením. Ďalšie informácie o vytváraní grafov nájdete v článku Základné typy grafov.
Poznámka: Pre pohodlie pri písaní vzorcov boli vo vzorovom súbore vytvorené názvy parametrov Binomické rozdelenie: n a p.

Vzorový súbor ukazuje rôzne výpočty pravdepodobnosti pomocou funkcií MS EXCEL:

Ako vidíte na obrázku vyššie, predpokladá sa, že:
- Nekonečná populácia, z ktorej sa odoberá vzorka, obsahuje 10 % (alebo 0,1) platných prvkov (parameter p, tretí argument funkcie = BINOM.DIST() )
- Na výpočet pravdepodobnosti, že vo vzorke 10 prvkov (parametr n, druhý argument funkcie) bude presne 5 platných prvkov (prvý argument), musíte napísať vzorec: =BINOM.DIST(5; 10; 0,1; FALSE)
- Posledný, štvrtý prvok je nastavený = FALSE, t.j. funkčná hodnota sa vráti hustota distribúcie .
Ak je hodnota štvrtého argumentu = TRUE, potom funkcia BINOM.DIST() vráti hodnotu kumulatívna distribučná funkcia alebo jednoducho Distribučná funkcia. V tomto prípade môžete vypočítať pravdepodobnosť, že počet dobrých prvkov vo vzorke bude z určitého rozsahu, napríklad 2 alebo menej (vrátane 0).
Aby ste to dosiahli, musíte napísať vzorec: = BINOM.DIST(2; 10; 0,1; TRUE)
Poznámka: Pre neceločíselné hodnoty x, . Napríklad nasledujúce vzorce vrátia rovnakú hodnotu: =BINOM.DIST( 2 ; 10; 0,1; PRAVDA)=BINOM.DIST( 2,9 ; 10; 0,1; PRAVDA)
Poznámka: Vo vzorovom súbore hustota pravdepodobnosti A distribučná funkcia vypočítané aj pomocou definície a funkcie NUMBERCOMB() .
Distribučné ukazovatele
IN vzorový súbor na pracovnom hárku Príklad Existujú vzorce na výpočet niektorých distribučných ukazovateľov:
- =n*p;
- (štandardná odchýlka na druhú) = n*p*(1-p);
- = (n+1)*p;
- =(1-2*p)*ROOT(n*p*(1-p)).
Poďme odvodiť vzorec matematické očakávanieBinomické rozdelenie použitím Bernoulliho okruh .
Podľa definície náhodná premenná X in Bernoulliho schéma(Bernoulliho náhodná premenná) má distribučná funkcia :

Táto distribúcia sa nazýva Bernoulliho distribúcia .
Poznámka : Bernoulliho distribúcia- špeciálny prípad Binomické rozdelenie s parametrom n=1.
Vygenerujme 3 polia so 100 číslami, z ktorých každé má inú pravdepodobnosť úspechu: 0,1; 0,5 a 0,9. Ak to chcete urobiť v okne Generovanie náhodných čísel Nastavme nasledujúce parametre pre každú pravdepodobnosť p:

Poznámka: Ak nastavíte možnosť Náhodný rozptyl (Náhodné semeno), potom môžete vybrať konkrétnu náhodnú množinu vygenerovaných čísel. Napríklad nastavením tejto možnosti =25 môžete generovať rovnaké sady náhodných čísel na rôznych počítačoch (ak sú, samozrejme, rovnaké parametre distribúcie). Hodnota voľby môže mať celočíselné hodnoty od 1 do 32 767 Náhodný rozptyl môže byť mätúce. Bolo by lepšie to preložiť ako Vytočte číslo s náhodnými číslami .
Vo výsledku budeme mať 3 stĺpce po 100 číslach, na základe ktorých vieme napr. odhadnúť pravdepodobnosť úspechu p podľa vzorca: Počet úspechov/100(cm. príklad súboru GenerationBernoulli).

Poznámka: Pre Bernoulliho distribúcie s p=0,5 môžete použiť vzorec =RANDBETWEEN(0;1), ktorý zodpovedá .
Generovanie náhodných čísel. Binomické rozdelenie
Predpokladajme, že vo vzorke je 7 chybných produktov. To znamená, že je „veľmi pravdepodobné“, že sa podiel chybných výrobkov zmenil p, čo je charakteristické pre náš výrobný proces. Hoci je takáto situácia „veľmi pravdepodobná“, existuje možnosť (riziko alfa, chyba 1. typu, „falošný poplach“), že p zostal nezmenený a zvýšený počet chybných výrobkov bol spôsobený náhodným výberom vzoriek.
Ako je možné vidieť na obrázku nižšie, 7 je počet chybných produktov, ktoré sú prijateľné pre proces s p=0,21 pri rovnakej hodnote Alfa. To ilustruje, že keď sa prekročí prahová hodnota chybných položiek vo vzorke, p„s najväčšou pravdepodobnosťou“ sa zvýšil. Fráza „s najväčšou pravdepodobnosťou“ znamená, že existuje len 10 % pravdepodobnosť (100 % – 90 %), že odchýlka percenta chybných výrobkov nad prahovú hodnotu je spôsobená iba náhodnými dôvodmi.

Prekročenie prahového počtu chybných produktov vo vzorke teda môže slúžiť ako signál, že proces sa narušil a začali sa vyrábať použité produkty. O vyššie percento chybných výrobkov.
Poznámka: Pred MS EXCEL 2010 mal EXCEL funkciu CRITBINOM(), ktorá je ekvivalentom BINOM.INV(). CRITBINOM() je ponechaný v MS EXCEL 2010 a vyššom kvôli kompatibilite.
Vzťah binomického rozdelenia k iným rozdeleniam
Ak parameter nBinomické rozdelenie inklinuje k nekonečnu a p má tendenciu k 0, potom v tomto prípade Binomické rozdelenie možno priblížiť. Môžeme formulovať podmienky, kedy aproximácia Poissonovo rozdelenie funguje dobre:
- p(menej p a viac n, čím presnejšia je aproximácia);
- p >0,9 (zvažujem to q =1- p, výpočty v tomto prípade musia byť vykonané cez q(A X je potrebné nahradiť n - X). Preto čím menej q a viac n, čím presnejšia je aproximácia).
O 0,110 Binomické rozdelenie možno priblížiť.
Na druhej strane Binomické rozdelenie môže slúžiť ako dobrá aproximácia, keď je veľkosť populácie N Hypergeometrické rozdelenie veľa väčšia veľkosť vzorky n (t.j. N>>n alebo n/N Viac o vzťahu medzi vyššie uvedenými rozdeleniami sa dočítate v článku. Sú tam uvedené aj príklady aproximácie a vysvetlené podmienky, kedy je to možné a s akou presnosťou .
RADY: O ďalších distribúciách MS EXCEL sa dočítate v článku.